Highlights
- Team-specific critics for competitive HARL (HAPPO-style) in IsaacLab.
- Plug-and-play adversarial environments with curriculum learning.
- Robust emergent behavior and role specialization across morphologies.
Training robust, competitive policies across morphology-diverse robot teams.
*Equal contribution. 1Utah State University. 2US DEVCOM Army Research Laboratory.
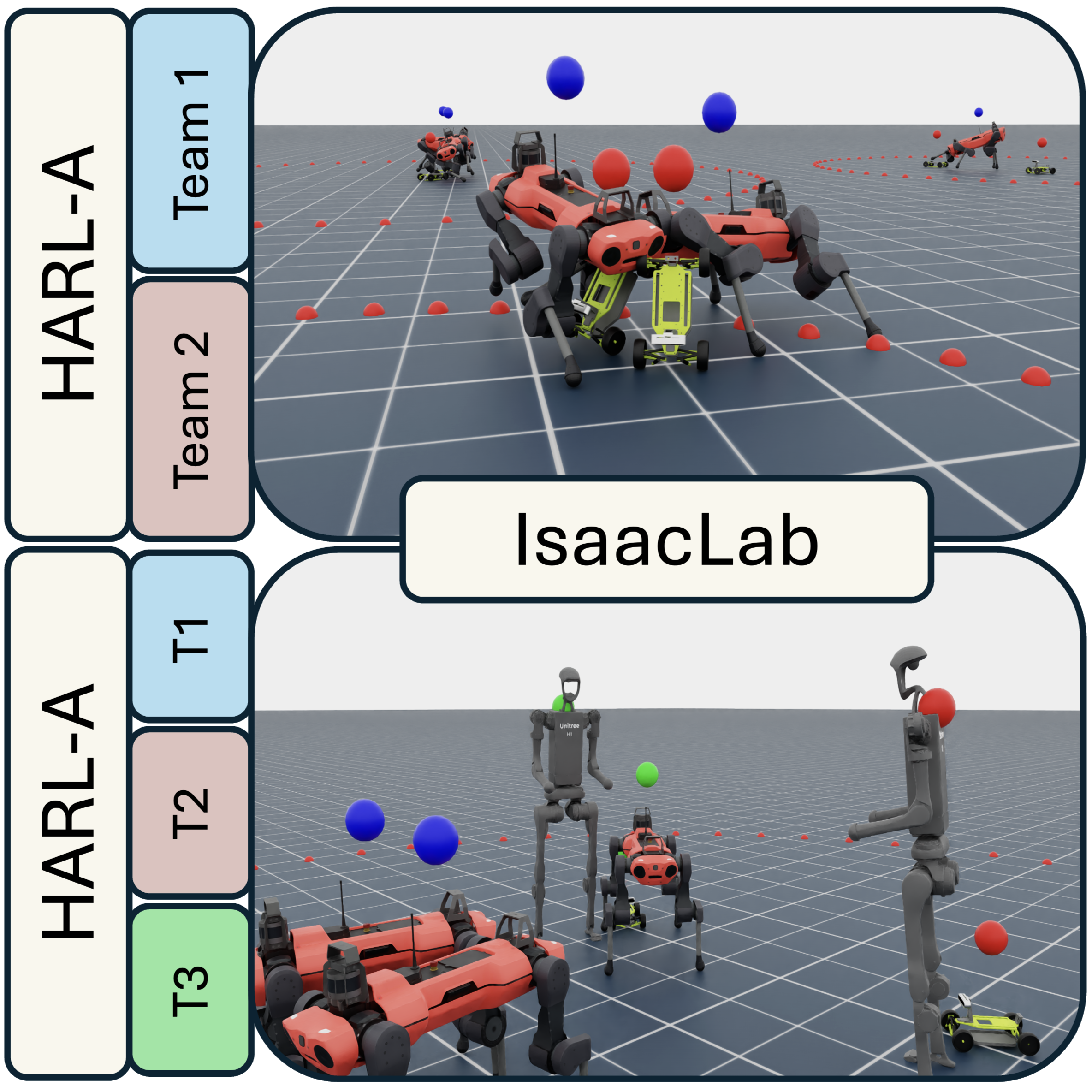
Heterogeneous adversarial multi-agent settings in IsaacLab. Top: quadruped teams in Sumo with Leatherback rovers.
MARL is central to robotic systems cooperating in dynamic environments. While prior work has focused on these collaborative settings, adversarial interactions are equally critical for real-world applications such as pursuit-evasion, security, and competitive manipulation. In this work, we extend the IsaacLab framework to support scalable training of adversarial policies in high-fidelity physics simulations. We introduce a suite of adversarial MARL environments featuring heterogeneous agents with asymmetric goals and capabilities. Our platform integrates a competitive variant of HAPPO, enabling efficient training and evaluation under adversarial dynamics. Experiments across several benchmark scenarios demonstrate the framework’s ability to model and train robust policies for morphologically diverse multi-agent competition while maintaining high throughput and simulation realism. Code and benchmarks are available at: https://directlab.github.io/IsaacLab-HARL/.
Highlights
Demonstration video: heterogeneous adversarial multi-agent learning in IsaacLab.
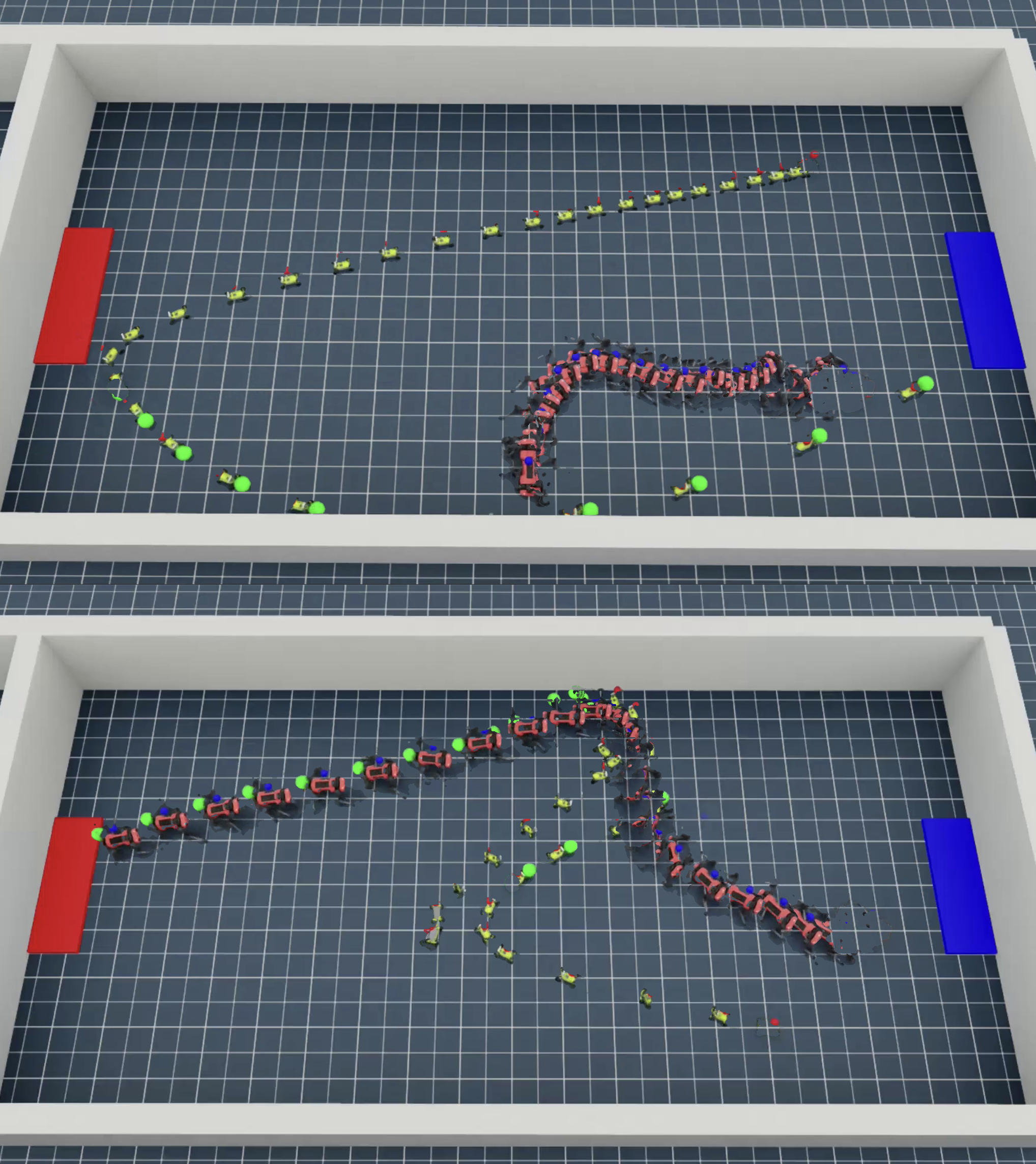
Quadrupeds and wheeled rovers compete to force opponents out of a ring. Trained with curriculum: walk → push block → adversarial Sumo.

Adversarial ball manipulation with morphology-appropriate actions and team dictionaries; trained with leapfrog actor updates.
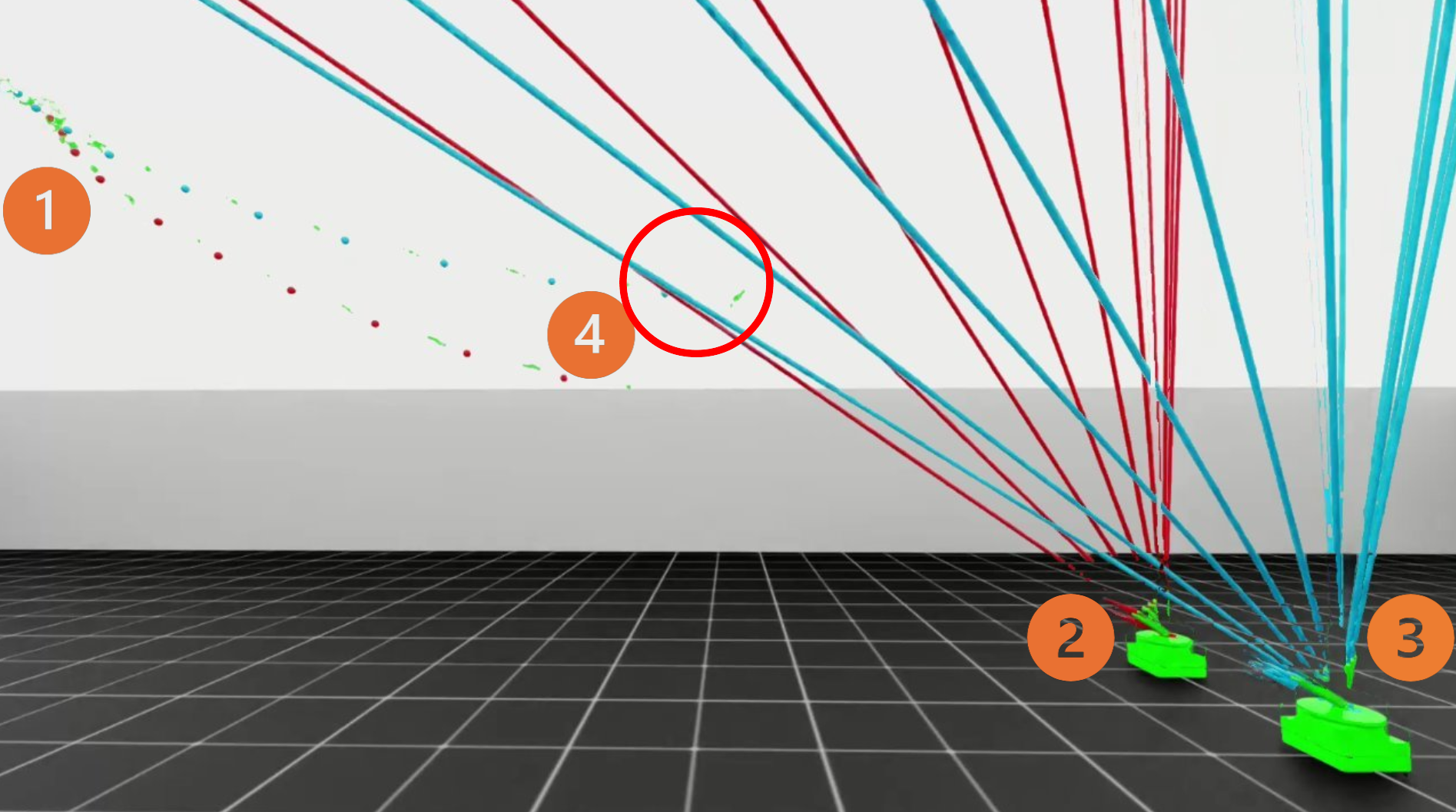
Drones attempt goal hits while MiniTanks ray-cast “laser-tag” knockouts. Demonstrates transfer and emergent competence in adversarial play.
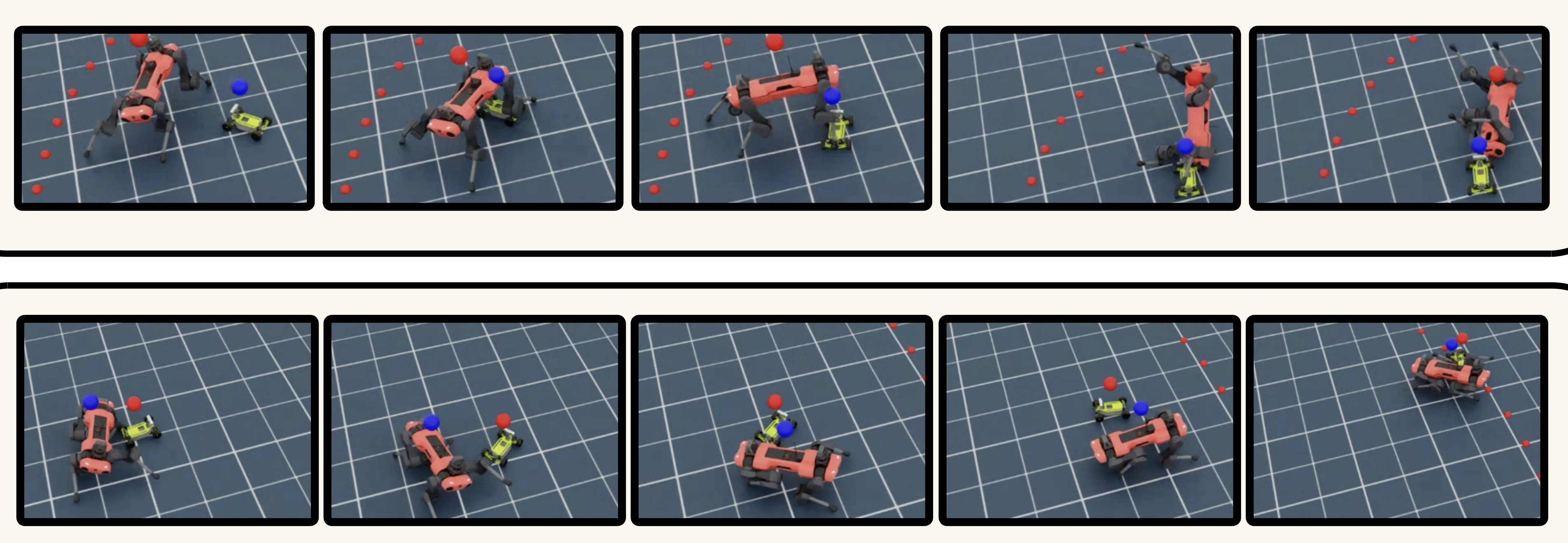
Sumo (Leatherback Stage 1)
Soccer (Leatherback Stage 1)
3D Galaga: Aerial–Ground Interception
Role specialization emerges: rovers destabilize legs; quadrupeds develop dragging maneuvers.
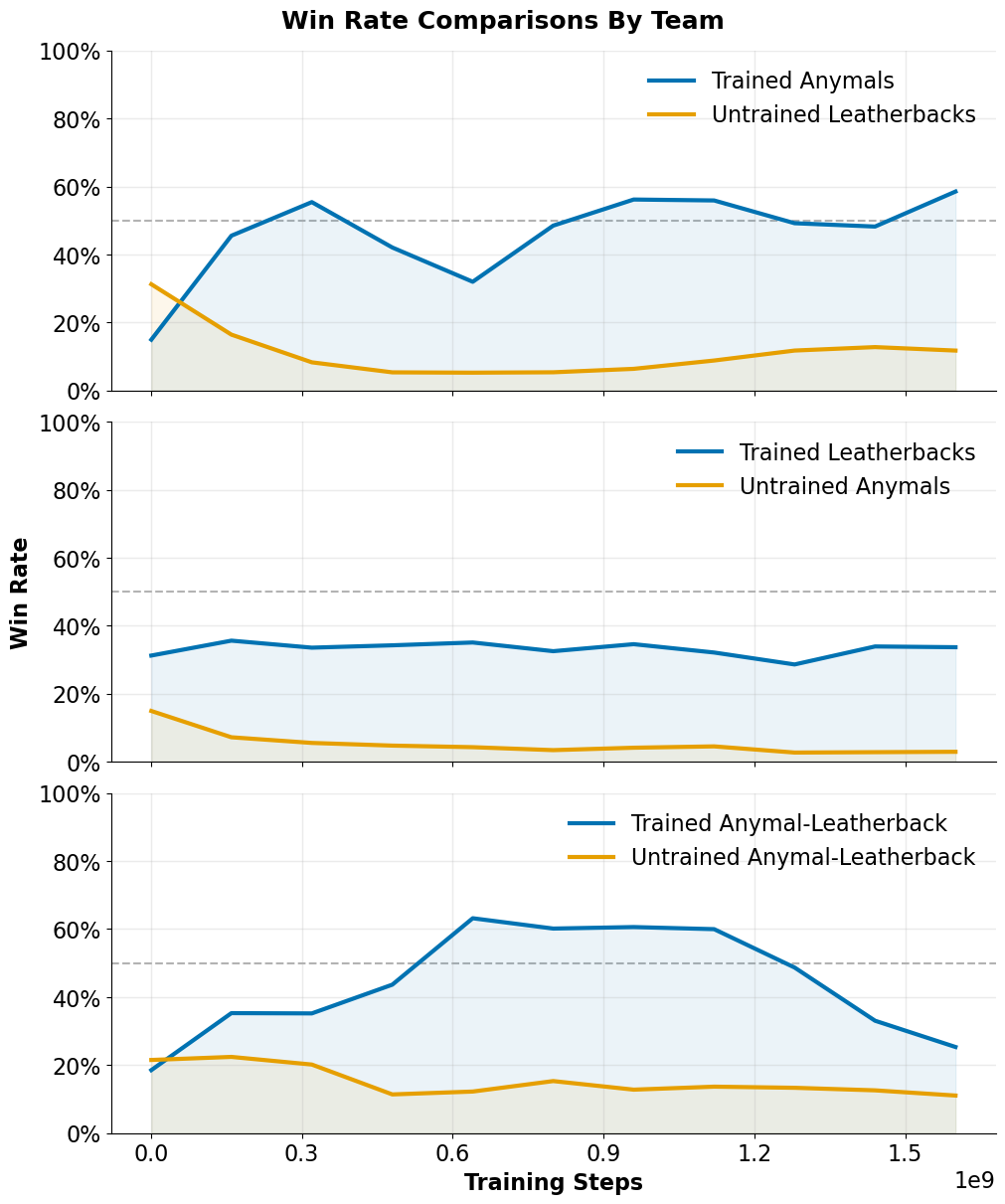
Trained policies consistently outperform initial versions across environments; both alternating and simultaneous training are effective.
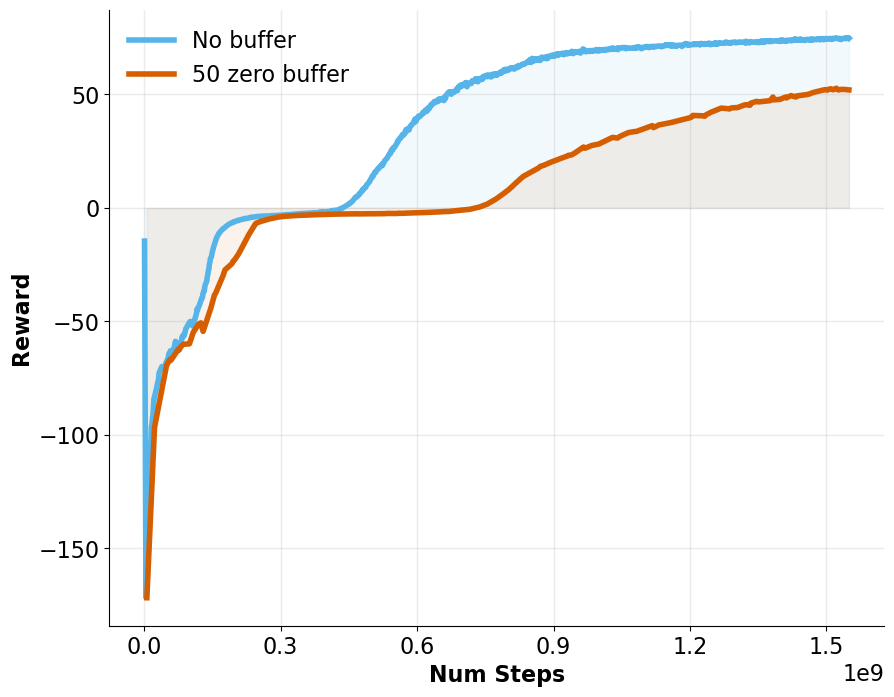
Zero-buffer enables consistent observation spaces across stages. Slightly slower early convergence but smoother stage transitions.
@article{peterson2025harlA,
title={A Framework for Scalable Heterogeneous Multi-Agent Adversarial Reinforcement Learning in IsaacLab},
author={Peterson, Isaac and Allred, Christopher and Morrey, Jacob and Harper, Mario},
journal={arXiv preprint arXiv:2510.01264},
year={2025}
}